
Welcome to my homepage. I am Song Wenfeng (宋文凤), an Associate Professor at Beijing Information Science and Technology University, specializing in digital human generation and reconstruction with a particular emphasis on medical applications. I earned both my Master’s and Doctoral degrees from Beihang University, under the mentorship of Professor Wang Huafeng (王华锋) during my Master’s program and Academician Zhao Qinping (赵沁平) during my Doctoral studies.
My research interests include virtual reality and computer vision with medical applications (e.g., human-scene interaction, medical image analysis) especially in the field of virtual human reconstruction. The experience in the State Key Laboratory of Virtual Reality Technology and System of Beihang motivates my interest and deep understanding of deep learning on Computer-assisted Diagnosis (CAD). My research domain is virtual reality for medical education and environment perception based on deep learning, including object detection based on image and video including unbalance dataset, depth estimation, person reid, UAV tracking.
🔥 News
- 2024.12: 🎉🎉 One paper is accepted to AAAI 2025.
- 2024.06: 🎉🎉 One paper is accepted to TMM.
- 2024.05: 🎉🎉 Two papers are accepted to TVCG.
- 2024.03: 🎉🎉 Two papers are accepted to CVPR 2024.
- 2023.12: 🎉🎉 One paper is accepted to AAAI 2024.
- 2023.12: 🎉🎉 One paper is accepted to TIP.
- 2023.07: 🎉🎉 One paper is accepted to ICCV 2023.
- 2023.05: 🎉🎉 One paper is accepted to TVCG.
- 2023.05: 🎉🎉 One paper is accepted to IJCV.
- 2023.01: 🎉🎉 One paper is accepted to TPAMI.
📝 Selected Publications
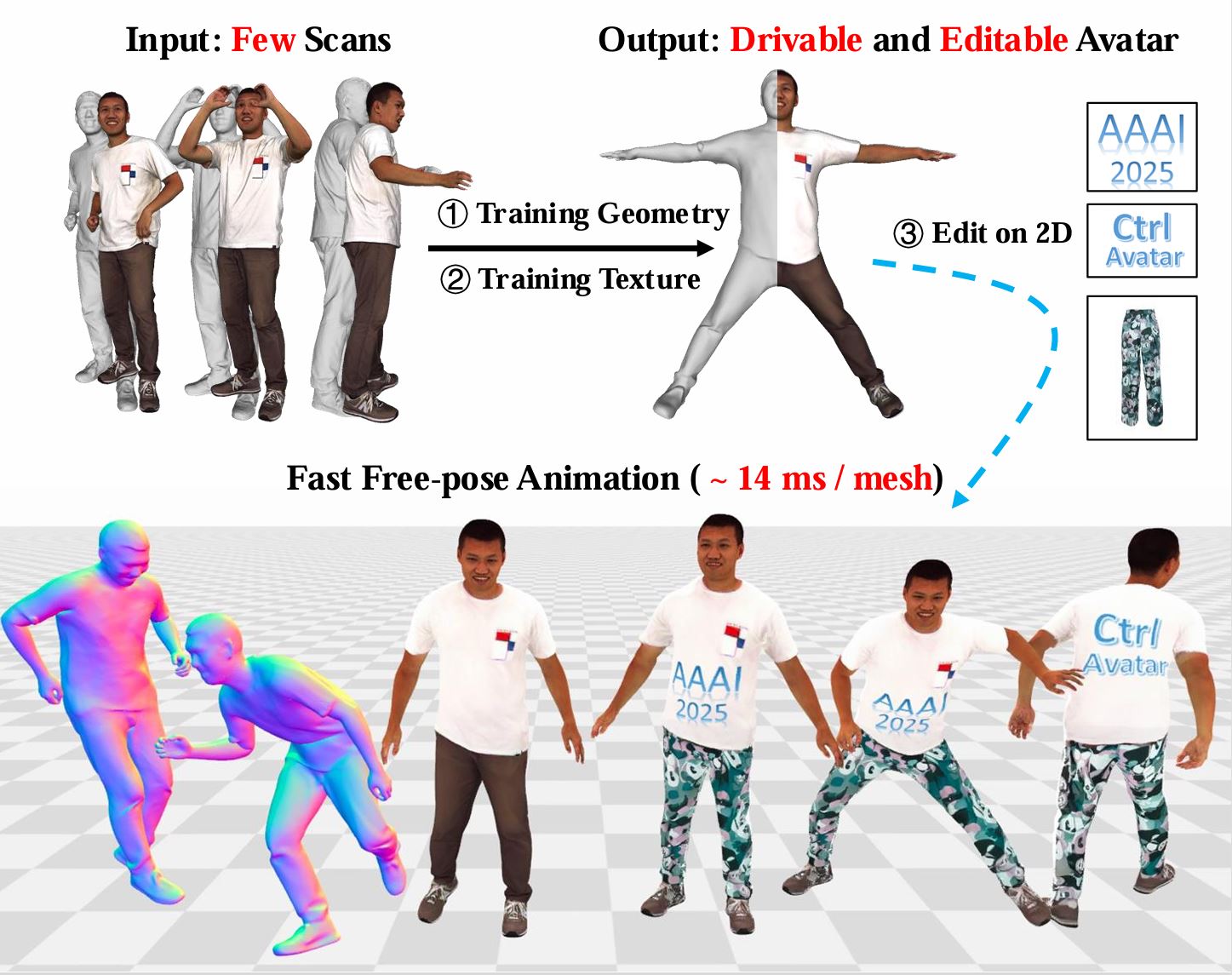
CtrlAvatar: Controllable Avatars Generation via Disentangled Invertible Networks.
Wenfeng Song, Yang Ding, Fei Hou, Shuai Li*, Aimin Hao, Xia Hou.
AAAI Conference on Artificial Intelligence (AAAI), 2025.
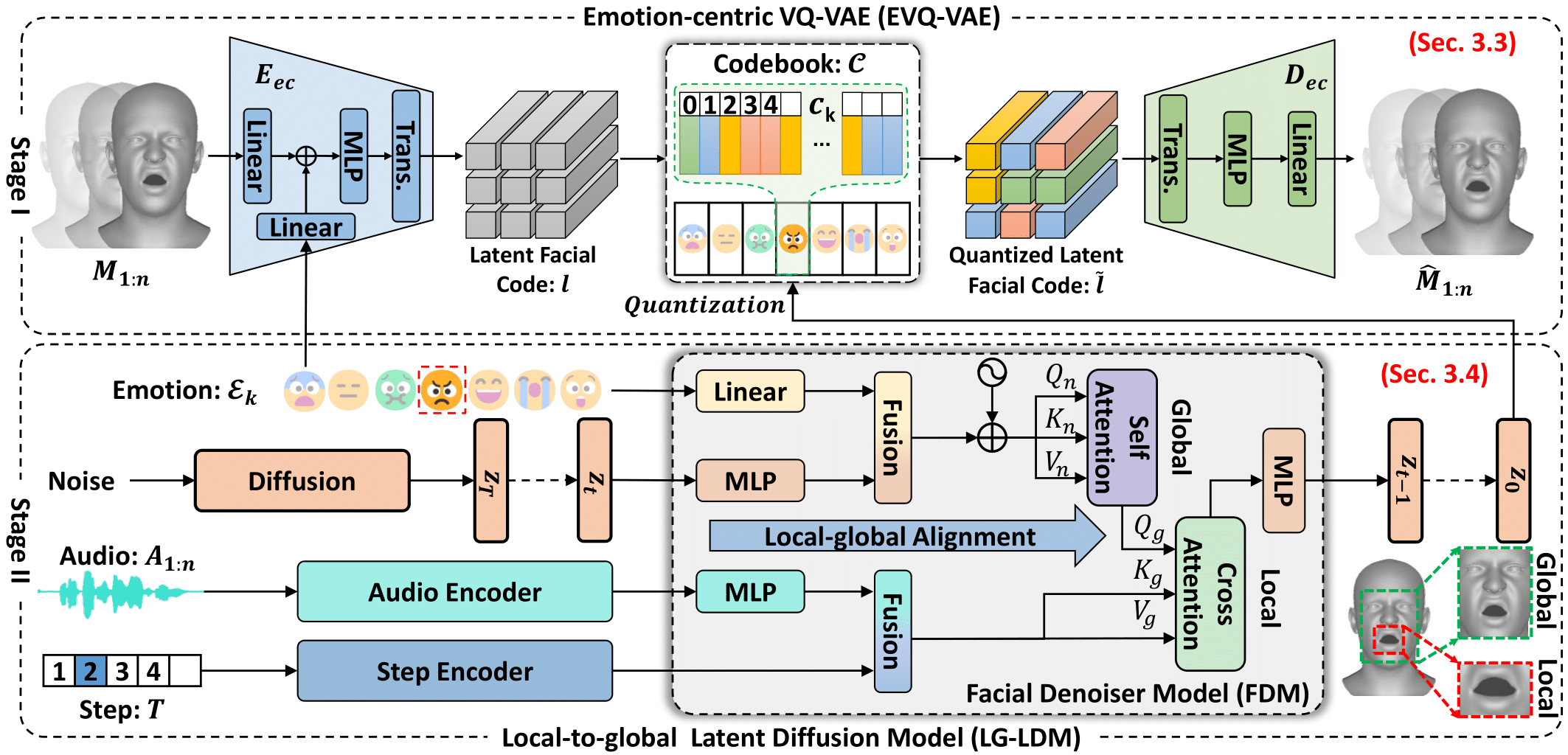
Expressive 3D Facial Animation Generation Based on Local-to-global Latent Diffusion.
Wenfeng Song, Xuan Wang, Yiming Jiang, Shuai Li*, Aimin Hao, Xia Hou, Hong Qin.
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2024, 30(11): 7397-7407.
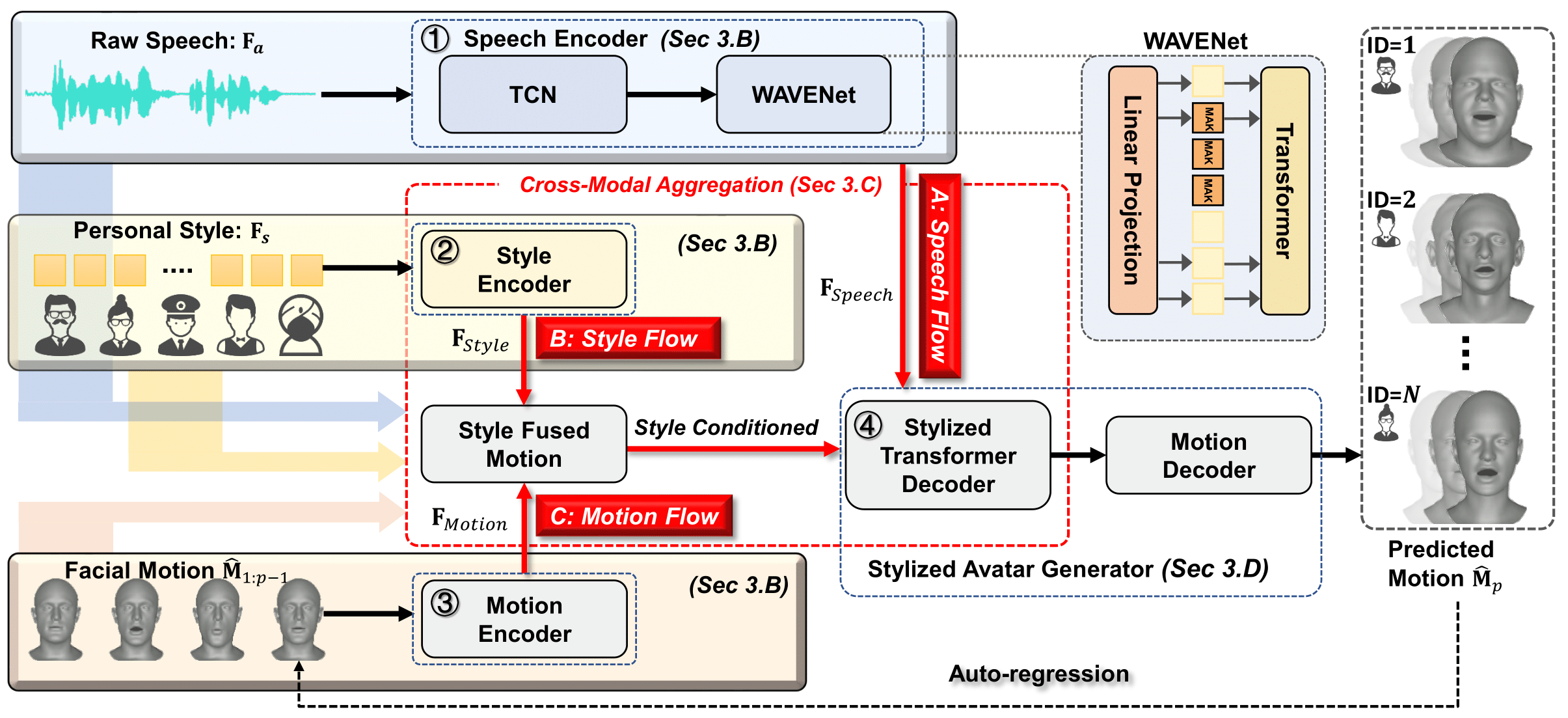
TalkingStyle: Personalized Speech-Driven 3D Facial Animation with Style Preservation.
Wenfeng Song, Xuan Wang, Shi Zheng, Shuai Li*, Aimin Hao, Xia Hou.
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2024.
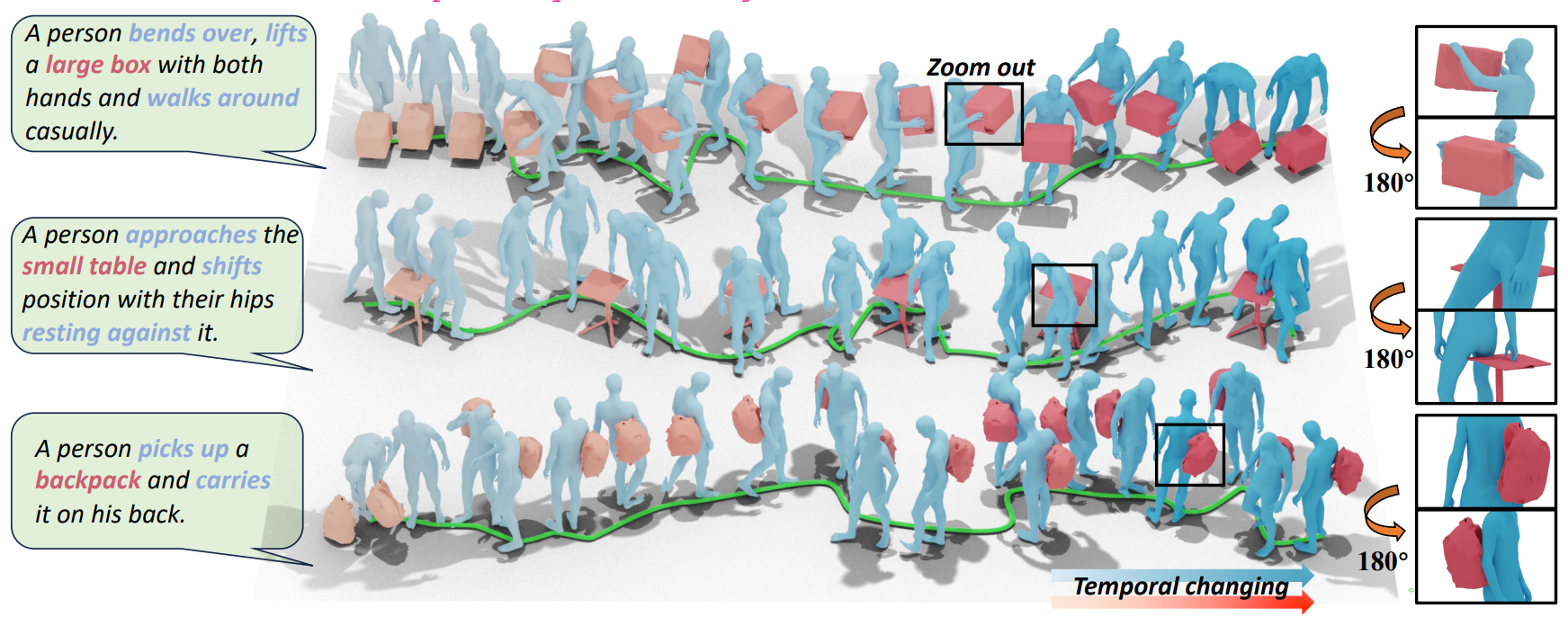
HOIAnimator: Generating Text-prompt Human-object Animations using Novel Perceptive Diffusion Models.
Wenfeng Song, Xinyu Zhang, Shuai Li, Yang Gao, Aimin Hao, Xia Hou, Chenglizhao Chen, Ning Li, Hong Qin.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024: 811-820.
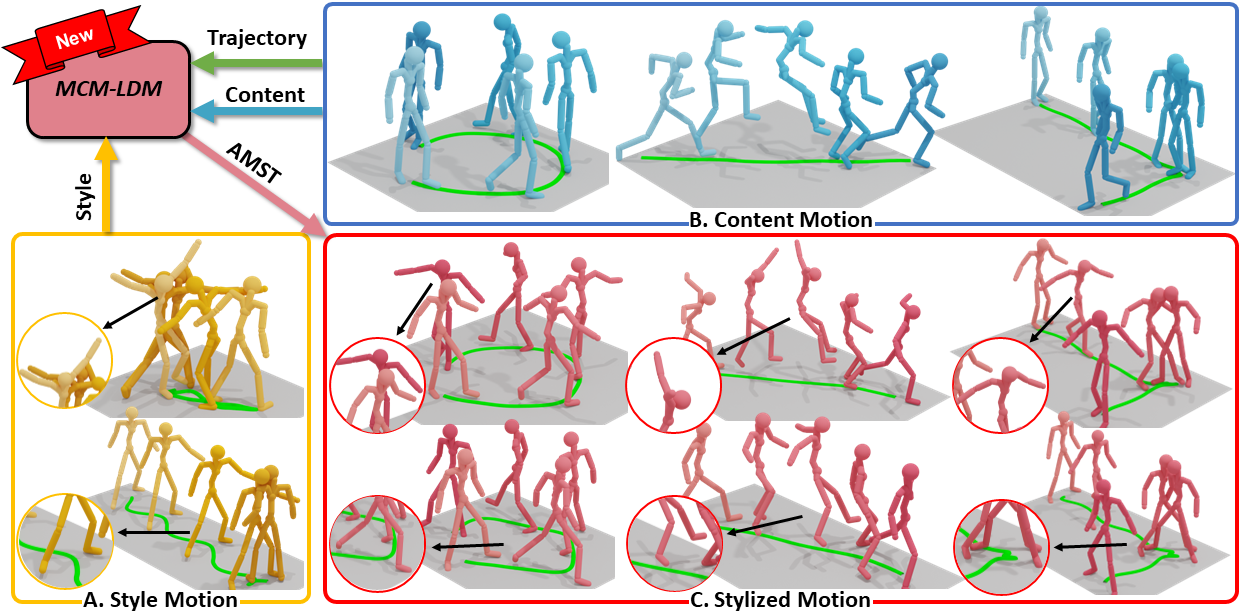
Arbitrary Motion Style Transfer with Multi-condition Motion Latent Diffusion Model.
Wenfeng Song, Xingliang Jin, Shuai Li, Chenglizhao Chen, Aimin Hao, Xia Hou, Ning Li, Hong Qin.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024: 821-830.
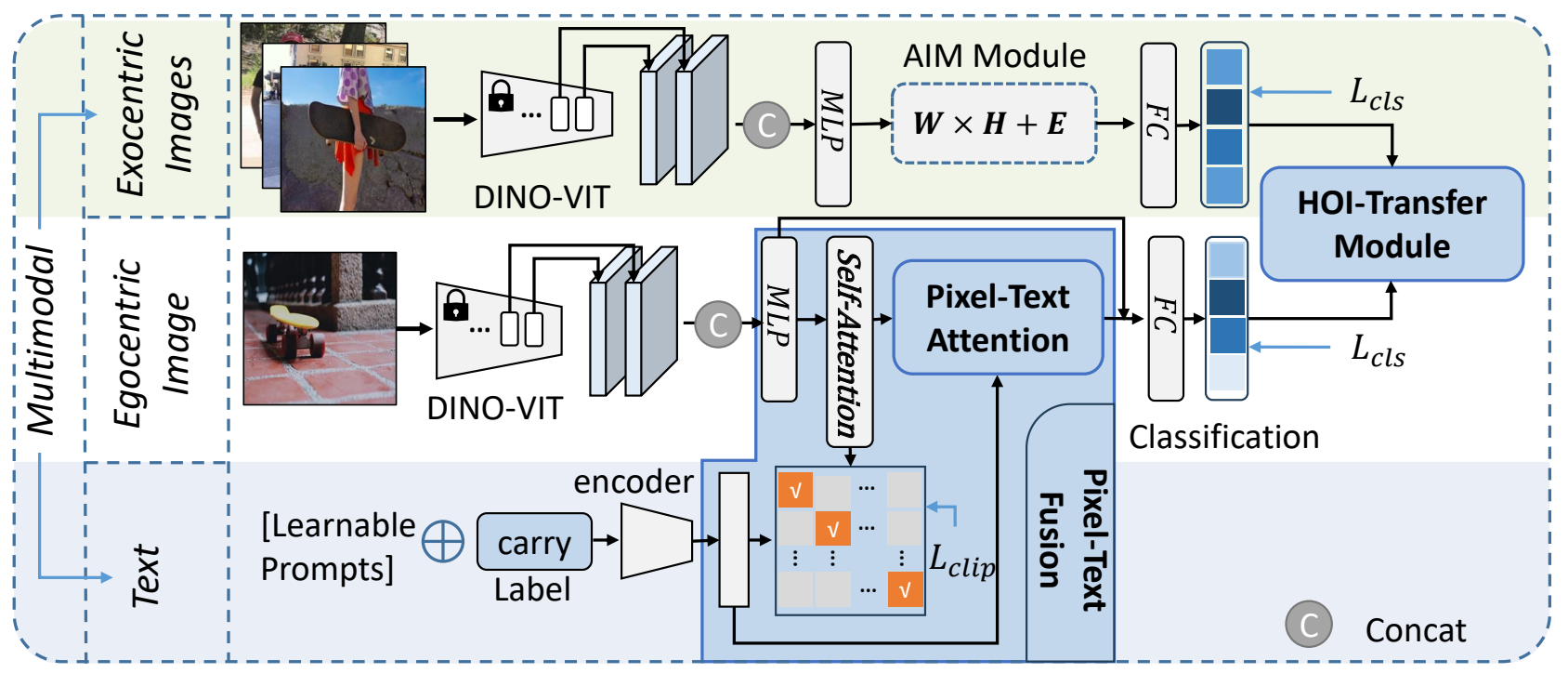
Weakly Supervised Multimodal Affordance Grounding for Egocentric Images.
Lingjing Xu, Yang Gao, Wenfeng Song, Aimin Hao.
AAAI Conference on Artificial Intelligence (AAAI), 2024, 38(6): 6324-6332.
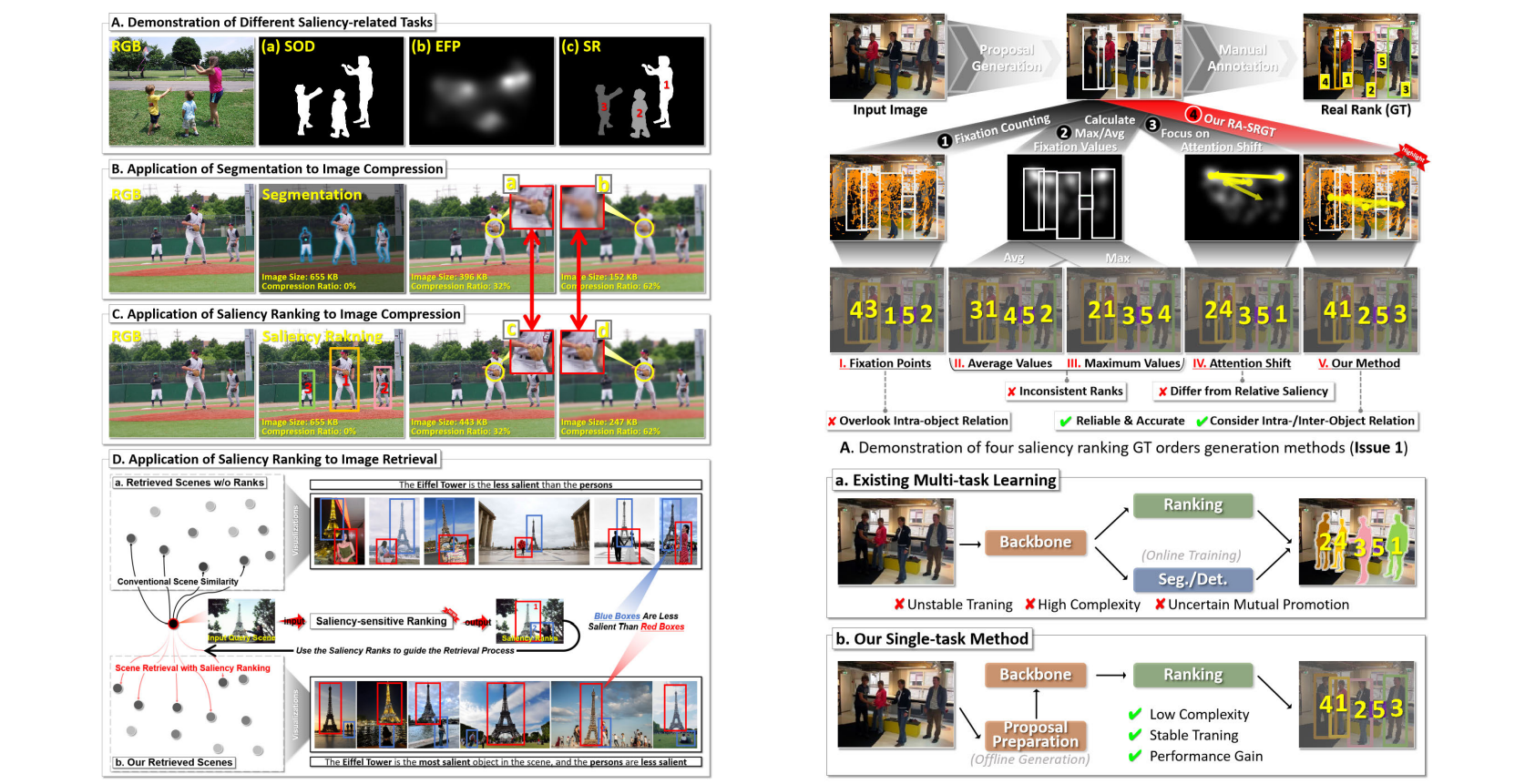
Rethinking Object Saliency Ranking: A Novel Whole-Flow Processing Paradigm.
Mengke Song, Linfeng Li, Dunquan Wu, Wenfeng Song, Chenglizhao Chen.
IEEE Transactions on Image Processing (TIP), 2023, 33: 338-353.
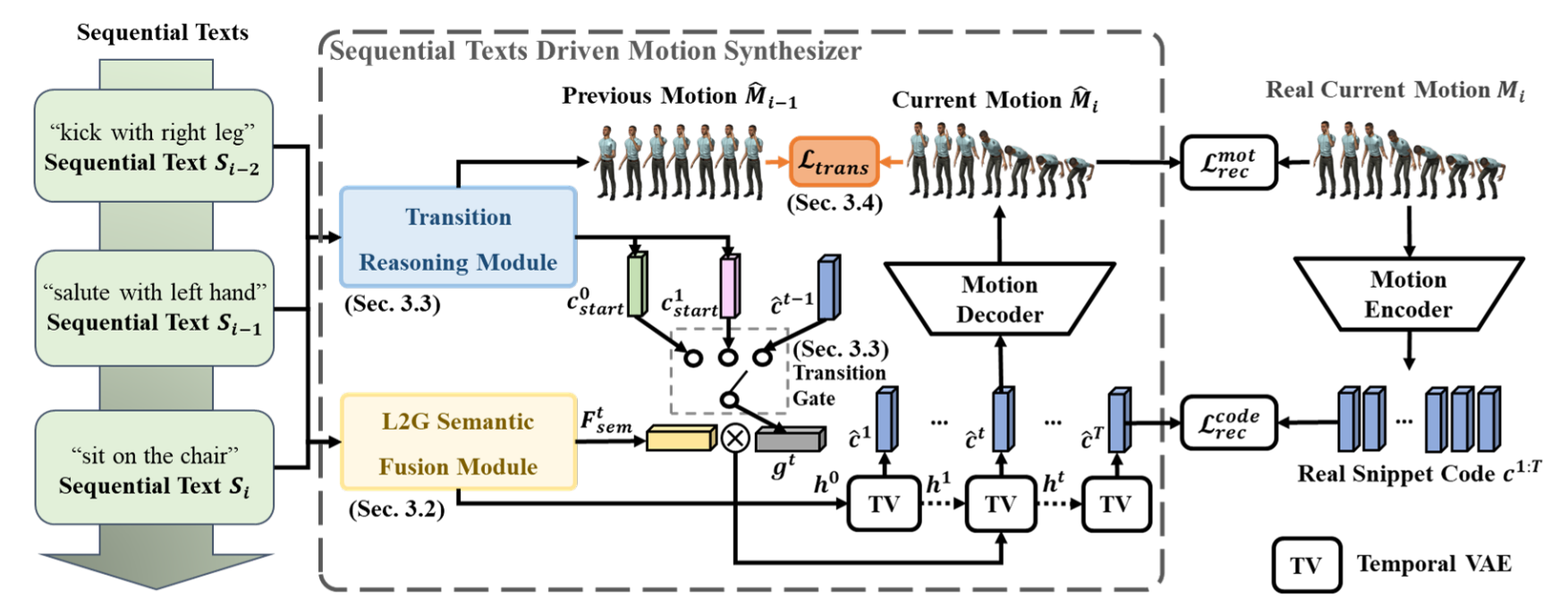
Sequential texts driven cohesive motions synthesis with natural transitions.
Shuai Li, Sisi Zhuang, Wenfeng Song*, Xinyu Zhang, Hejia Chen, Aimin Hao.
IEEE/CVF International Conference on Computer Vision (ICCV), 2023: 9498-9508.
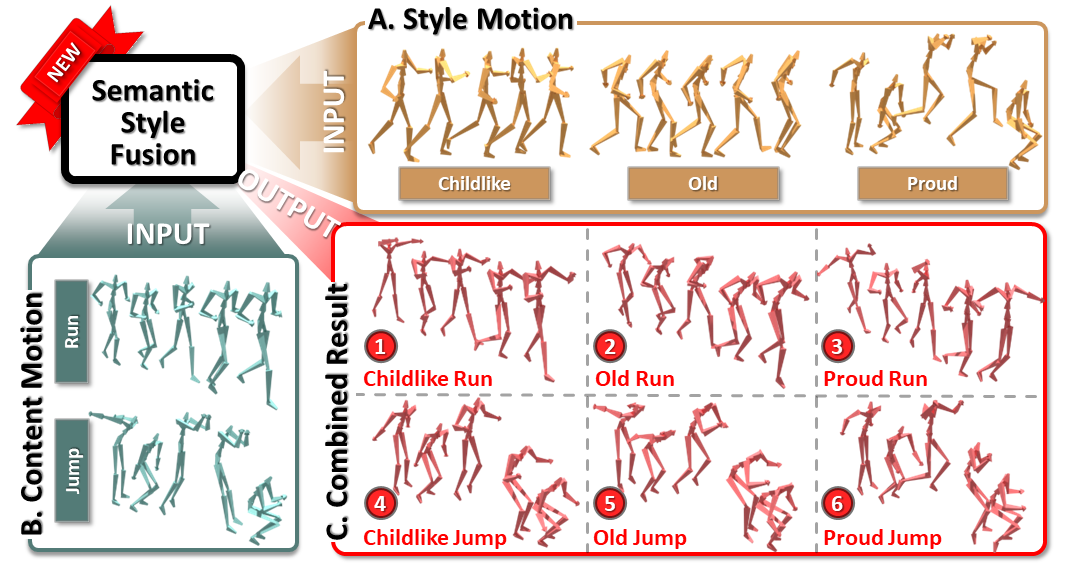
FineStyle: Semantic-Aware Fine-Grained Motion Style Transfer with Dual Interactive-Flow Fusion.
Wenfeng Song, Xingliang Jin, Shuai Li*, Chenglizhao Chen, Aimin Hao, Xia Hou.
IEEE Transactions on Visualization and Computer Graphics, 2023, 29(11): 4361-4371.
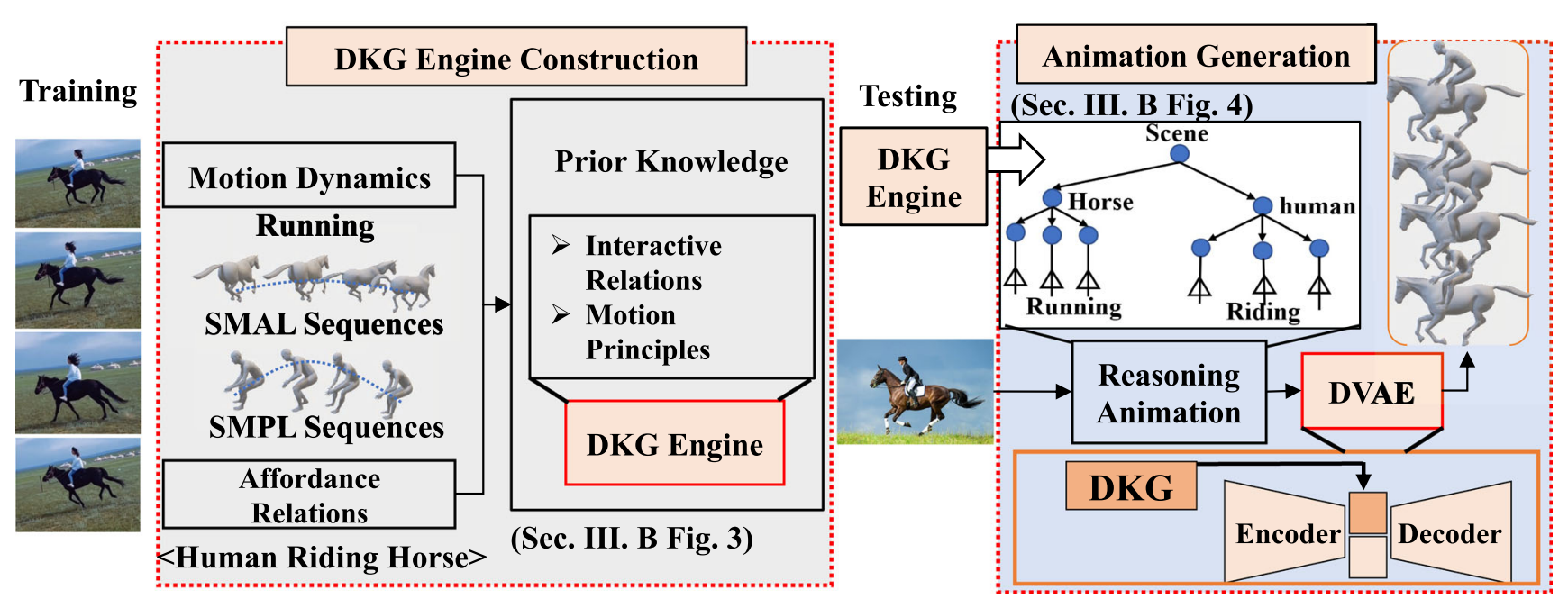
Wenfeng Song, Xinyu Zhang, Yuting Guo, Shuai Li, Aimin Hao, Hong Qin.
International Journal of Computer Vision (IJCV), 2023, 131(11): 2816-2844.
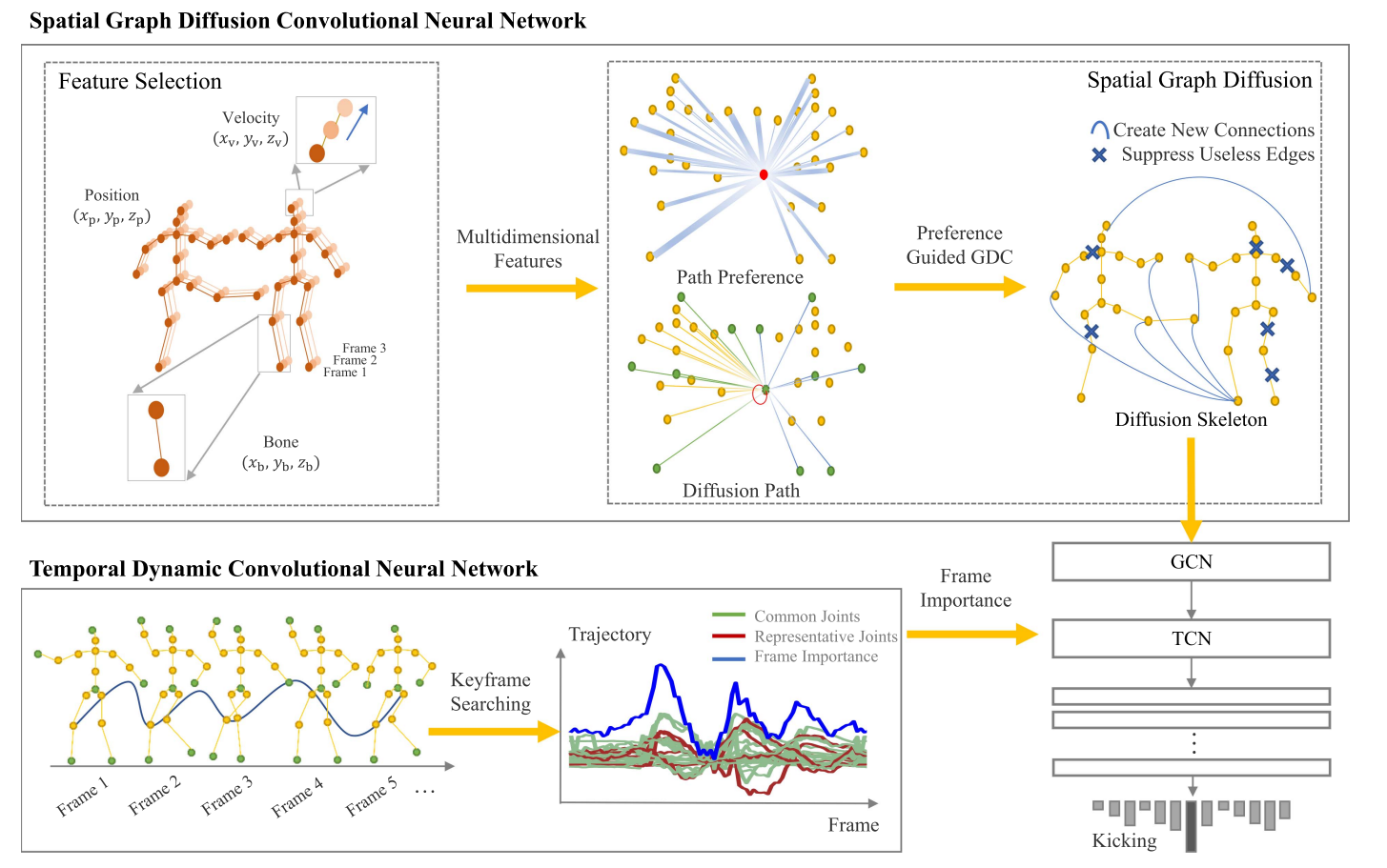
Graph Diffusion Convolutional Network for Skeleton Based Semantic Recognition of Two-Person Actions.
Shuai Li, Xinxue He, Wenfeng Song*, Aimin Hao, Hong Qin.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023, 45(7): 8477-8493.

Dynamic attention augmented graph network for video accident anticipation.
Wenfeng Song, Shuai Li*, Tao Chang, Ke Xie, Aimin Hao, Hong Qin.
Pattern Recognition (PR), 2024, 147: 110071.
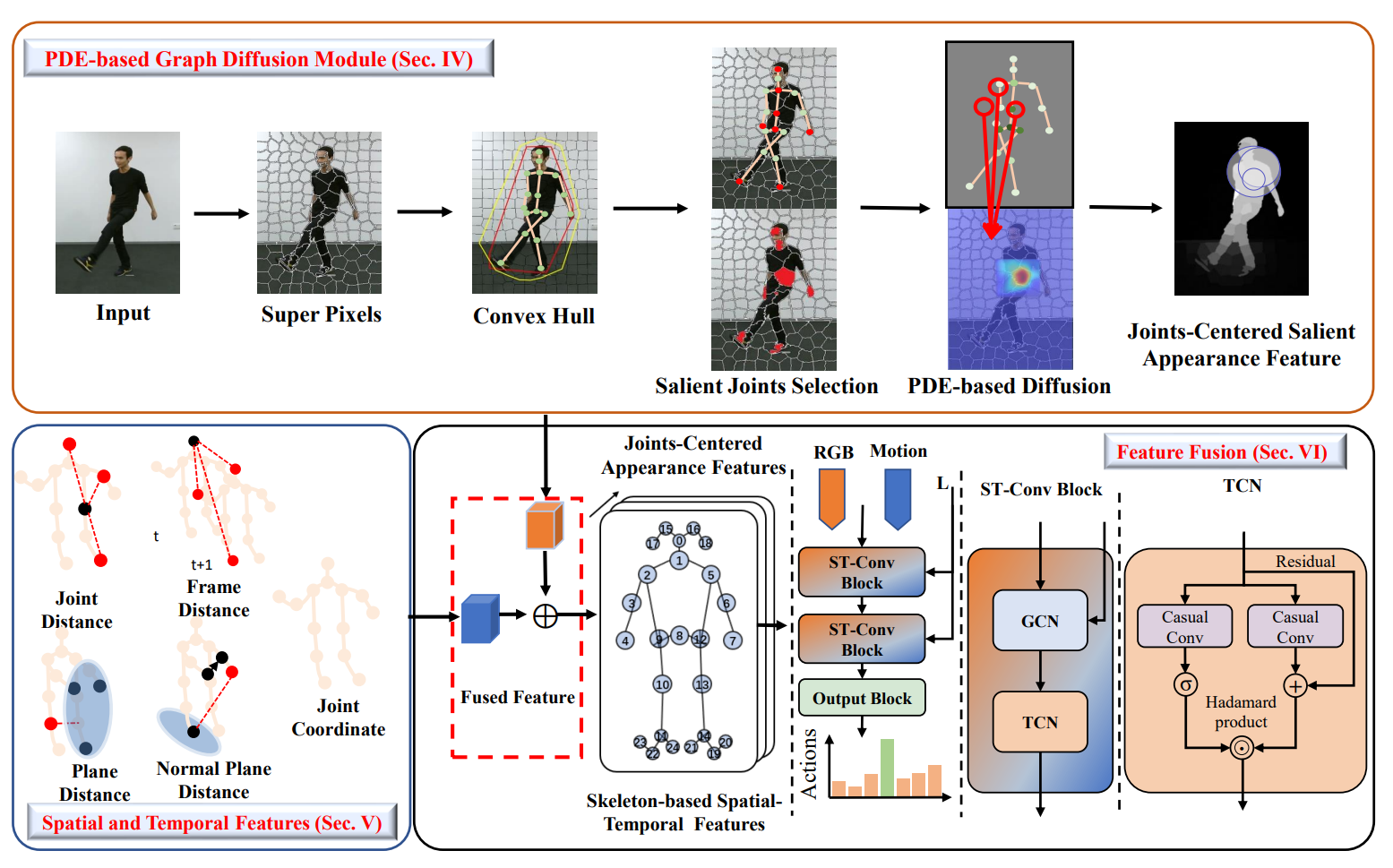
Joints-Centered Spatial-Temporal Features Fused Skeleton Convolution Network for Action Recognition.
Wenfeng Song, Tangli Chu, Shuai Li*, Nannan Li, Aimin Hao, Hong Qin.
IEEE Transactions on Multimedia (TMM), 2023, 26: 4602-4616.
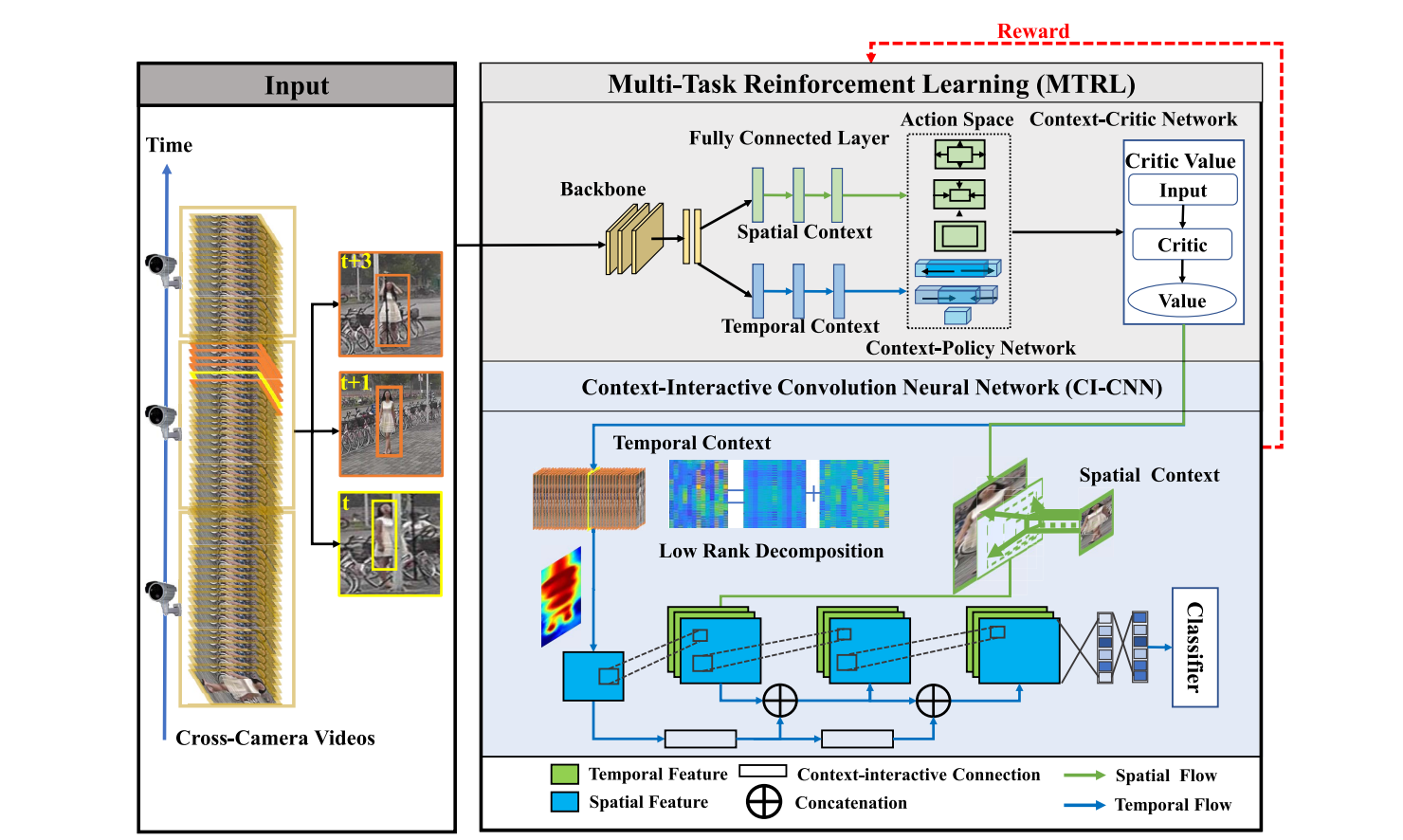
Context-interactive CNN for person re-identification.
Wenfeng Song, Shuai Li, Tao Chang, Aimin Hao, Qinping Zhao, Hong Qin.
IEEE Transactions on Image Processing (TIP), 2019, 29: 2860-2874.
📖 Educations
- 2015.09- 2020.08, Ph.D, Beihang University, Beijing
- 2012.09 - 2015.03, Master, Beihang University, Beijing